

Bring your data and code, we do the rest.
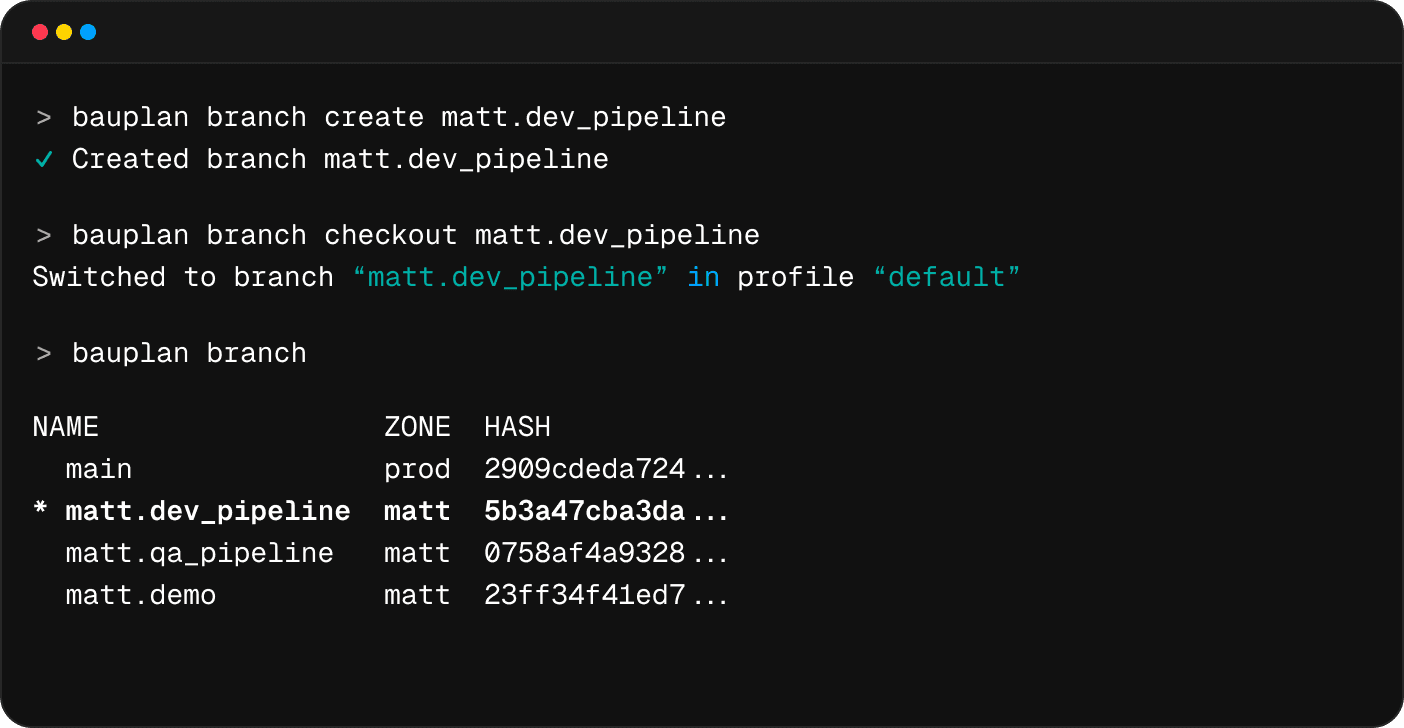
Branch. Create sandboxed branches of your data lake to develop pipelines without disrupting your production applications.
Run. Build complex SQL and Python pipelines, without dealing with containers, compute clusters and infrastructure.
Query. Run complex queries to explore data and power your data applications with the same runtime.
Merge. Integrate all your data workflows with your orchestration and CI/CD.

Data Lake version control
Instant branching of your Data Lake
Work together on your data, without disrupting the production environment.



Makes everything reproducible
Keep track of all changes in both your data and your code: no issue cannot be reproduced, no incident cannot be undone.
No lock-in
Your business logic code is completely abstracted from your infrastructure so you don’t have to refactor it if you want to move.
Leverage Iceberg open format to write back in your data lake and make tables available to other query engines and downstream systems.

Serverless runtime
No environment management
Express container images and environment requirements entirely in code for each function of your workload. Never worry about maintaining environments and backward compatibility.


10x better developer experience
Deploy data pipeline in the cloud in seconds from code. No special skills required, no need to deal with containerization, compute provisioning and cluster configurations ever again. Just SQL and Python.
Self-service interactive analytics
Explore interactively data with Bauplan query engine and build real-time analytics applications. Simplify by use the same compute engine for both data pipelines and synchronous queries.

